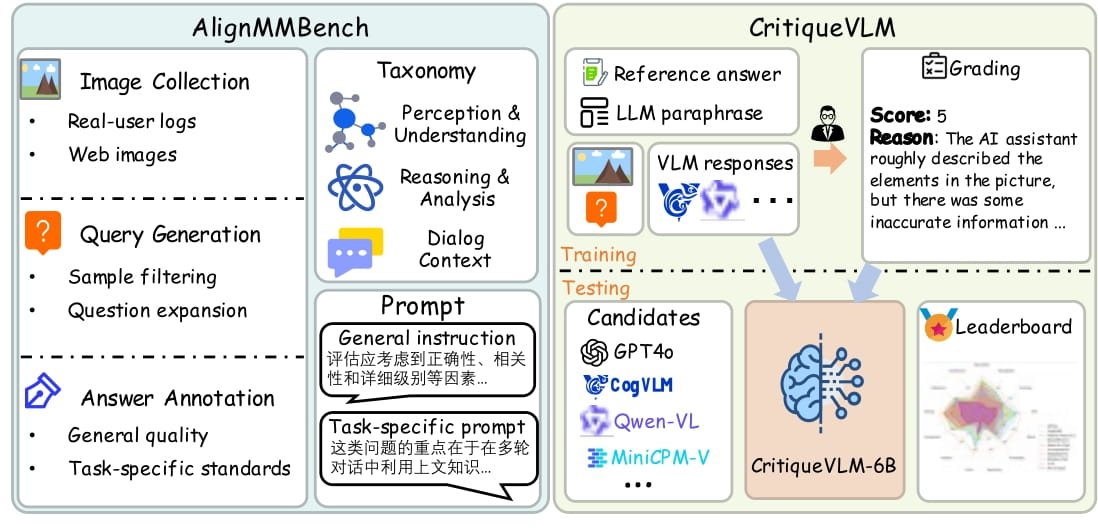
Evaluation results on AlignMMBench. The "Ref." column indicates the relative ranking of these models on opencompass, dominated by primarily English benchmarks.
| Models | Size | Ref. | Avg | Perception \& Understanding. | Reasoning \& Analysis | Context | Align. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Des. | Rec. | Cou. | OCR. | Mem. | Kno. | Rea. | Cha. | Pro. | Com. | Wri. | Coh. | Inc. | |||||
| Qwen2-VL | 72B | 1 | 6.51 | 7.39 | 6.64 | 6.64 | 7.60 | 7.09 | 6.32 | 4.00 | 7.16 | 5.89 | 6.57 | 7.72 | 6.37 | 5.26 | 1.54 |
| Claude | - | 4 | 6.51 | 7.68 | 6.89 | 6.79 | 7.02 | 7.10 | 6.28 | 4.06 | 7.11 | 5.20 | 5.92 | 7.98 | 7.02 | 5.52 | 1.45 |
| GPT-4o | - | 2 | 6.41 | 7.75 | 6.41 | 5.20 | 7.17 | 7.28 | 6.16 | 4.44 | 7.23 | 5.81 | 7.19 | 7.85 | 6.41 | 4.43 | 1.18 |
| CogVLM2 | 19B | 8 | 5.81 | 7.20 | 6.12 | 5.75 | 7.21 | 6.07 | 5.69 | 3.43 | 5.92 | 4.37 | 5.65 | 7.34 | 6.33 | 4.43 | 1.49 |
| InternVL-Chat | 26B | 5 | 5.62 | 7.12 | 6.00 | 5.51 | 6.63 | 4.99 | 5.08 | 3.35 | 5.98 | 3.98 | 6.33 | 7.26 | 6.31 | 4.48 | 1.12 |
| InternVL2 | 76B | 3 | 5.57 | 6.95 | 5.11 | 5.81 | 7.37 | 5.96 | 3.61 | 3.83 | 6.48 | 4.66 | 6.05 | 6.05 | 6.30 | 4.23 | 0.93 |
| MiniCPM | 8B | 6 | 5.42 | 7.18 | 5.37 | 5.46 | 6.23 | 4.46 | 5.35 | 3.34 | 4.83 | 3.69 | 5.99 | 7.35 | 6.25 | 4.97 | 1.09 |
| Qwen-VL-Chat | 9B | 12 | 5.13 | 6.43 | 5.87 | 5.40 | 4.80 | 5.11 | 5.58 | 2.98 | 4.10 | 3.12 | 5.51 | 7.19 | 6.07 | 4.50 | 1.01 |
| InternLM-XC2-VL | 7B | 7 | 4.97 | 6.34 | 4.70 | 5.28 | 5.06 | 4.69 | 5.03 | 3.08 | 4.49 | 3.29 | 5.00 | 7.21 | 5.92 | 4.56 | 0.88 |
| DeepSeek-VL | 7B | 11 | 4.70 | 6.53 | 5.52 | 5.10 | 3.98 | 3.87 | 4.19 | 2.50 | 3.96 | 2.58 | 5.46 | 7.15 | 5.83 | 4.47 | 1.02 |
| Monkey-Chat | 9B | 10 | 4.70 | 6.04 | 4.88 | 5.57 | 4.66 | 4.18 | 4.96 | 3.01 | 4.00 | 2.61 | 4.87 | 6.29 | 6.15 | 3.96 | 0.96 |
| ShareGPT4V | 13B | 14 | 4.39 | 5.93 | 4.61 | 5.16 | 3.77 | 4.04 | 4.58 | 2.45 | 3.73 | 2.19 | 5.05 | 6.39 | 5.36 | 3.79 | 1.08 |
| LLava-v1.5 | 13B | 15 | 4.31 | 6.02 | 4.56 | 4.46 | 3.85 | 3.69 | 4.72 | 2.46 | 3.69 | 2.10 | 4.75 | 6.21 | 5.60 | 3.96 | 1.05 |
| Yi-VL | 34B | 13 | 4.25 | 4.79 | 4.78 | 5.19 | 3.33 | 3.58 | 4.47 | 2.42 | 3.25 | 2.08 | 4.72 | 6.61 | 5.87 | 4.13 | 1.20 |
| Phi-3-Vision | 4B | 9 | 4.08 | 4.48 | 3.53 | 4.75 | 4.10 | 3.48 | 3.16 | 2.56 | 4.40 | 2.85 | 4.34 | 5.51 | 5.85 | 4.07 | 0.86 |
| InstructBLIP | 9B | 16 | 3.31 | 4.11 | 4.61 | 4.11 | 2.77 | 3.05 | 2.92 | 1.76 | 2.58 | 1.12 | 3.36 | 3.17 | 5.42 | 4.02 | 1.09 |
| GPT-4o without image | - | - | 2.13 | 1.11 | 1.57 | 1.22 | 1.73 | 1.53 | 1.17 | 1.29 | 2.88 | 1.14 | 1.99 | 3.50 | 5.14 | 3.41 | - |